是什么
官网介绍 Kafka 是一个开源分布式事件流平台
一般作为中间件使用,通过 Kafka 来发布事件,订阅事件,达到削峰填谷,解耦的效果
主要概念和术语
Producers: 生产者,用于发布事件
Consumer: 消费者,用于消费事件
Topic: 可以理解为文件夹的概念,生产者和消费者都需要指定 Topic 来进行生产/消费活动
Broker: 可以理解为部署了 Kafka 的一台机器,高可用正是依赖于分布式
Partition: 分区,同一个 Topic 的数据是分布在不同的分区上的,可以通过指定 key 的方式来确保相同 key 的数据分布在同一个 Partition 上
设计
持久化
Kafka 的数据是持久化在硬盘上的,在普遍认知中,硬盘的速度是非常慢的,尤其是机械硬盘,那 Kafka 又是如果做到高吞吐的呢
6 个 7200 转 SATA RAID-5 阵列在顺序写的情况下可以达到 600MB/s 但是随机写只能 100k/s,这其中差了 6000 倍的性能
因此 Kafka 通过顺序写的方式在硬盘上也能做到非常高的吞吐量
常量复杂度
由于消息队列的特性,取数据从队列头取,加入数据加入到队列尾,这种操作的时间复杂度都是 O(1) 因此性能很高
不像数据库,需要维护 B-Tree 结构来提升查找速度
效率
批处理
频繁的小 I/O 操作和字节拷贝是影响性能的重要因素
Kafka 通过批处理的方式来解决频繁小 I/O 造成的性能问题
零拷贝
可参考:Efficient data transfer through zero copy - IBM Developer
Kafka 通过使用操作系统提供的零拷贝接口来减少字节拷贝次数
一次从文件读数据写到 socket 的流程
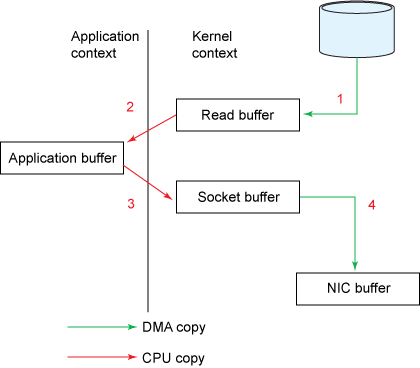
- 操作系统从硬盘中读取数据到内核空间的
pagecache中 - 应用从内核空间读数据到用户空间的
buffer中 - 应用将用户空间
buffer中的数据写入内核空间的socket buffer - 操作系统将数据从
socket buffer拷贝到NIC buffer中用于通过网络发送
上下文切换示意图
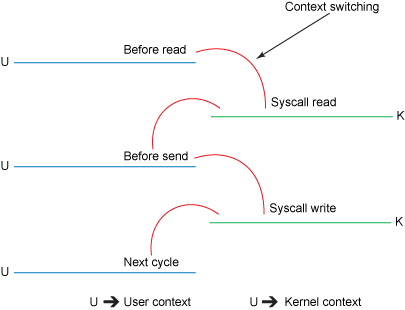
能看到,总共有 4 次数据拷贝,4 次上下文切换
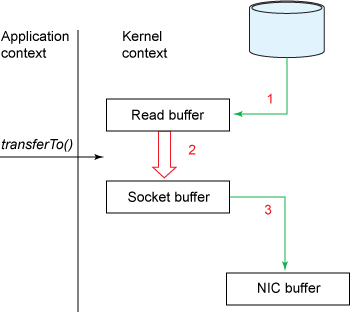
使用零拷贝之后流程变更如下
上线文切换变更如下
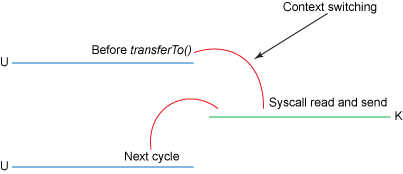
拷贝次数从 4 减少到 3 ,上下文切换次数从 4 减少到 2
如果您的网卡支持 gather ,可以进一步优化流程
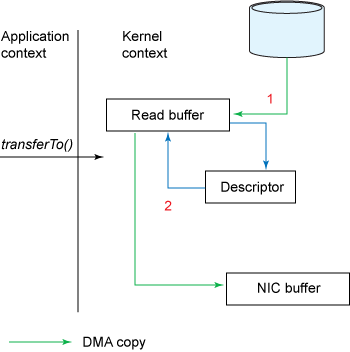
总共 2 次 DMA 拷贝,2 次上下文切换
端到端批量压缩
在消息队列场景下,CPU 和硬盘通常不是瓶颈,网络带宽才是
单条数据压缩对比批量数据压缩的压缩比是较差的,因为数据重复度越高,压缩才越有意义
例如 json 数据的 key 大都是相同的,多条一起压缩明显能获得更高的压缩比
Kafka 可以自动进行批量压缩
消息传输语义
- At most once - 消息可能会丢失,但绝不会重复
- At least once - 消息一定不会丢失,但可能会重复
- Exactly once - 每个消息仅被投递一次
Kafka 默认提供 At least once 的消息投递保证
Kafka 0.11.0 版本之后可以使用事务来保证 Exactly once 效果(需要使用的 Connector 支持)
Kafka 为什么快
- 本身的特性:队列的头尾操作时间复杂度均为 O(1)
- 硬盘顺序写:顺序写比随机写快数千倍
- 零拷贝:普通拷贝有 2 次 CPU copy,2 次 DMA copy,4 次上下文切换。使用零拷贝技术后减少为 2 次 DMA copy,2 次上下文切换
- 批处理:将多次小 I/O 打包处理
- 批量压缩:自动批量压缩数据,减少传输消耗
- 分布式:多台 Broker 分布式处理