起因
因为在 SQL 最左前缀疑问 这里看到的问题,讲讲一些对最左前缀的常见误解
原问题
为了方便,直接放截图了
答案
你这个问题非常有意思,里面涉及了挺多知识点的
且听我慢慢道来
首先,我在本地建了和你一样的表,有一点区别就是没有 KEY name_INX (name) 这个索引,因为这是个没用的索引,徒废资源
关于这个就是你所说的最左前缀了,已经有 KEY name_cid_INX(name, cid) 这个索引了,上面那个就没用了
另外再推荐一下,学习索引相关的时候可以使用 MySQL8.0 以上的版本,有 explain analyze 语句,这个和 explain 的区别在于会真的去执行 sql 而不是根据统计信息来推断,这个可以更好地知道 SQL 是如何执行的
好,下面正式开始回答问题
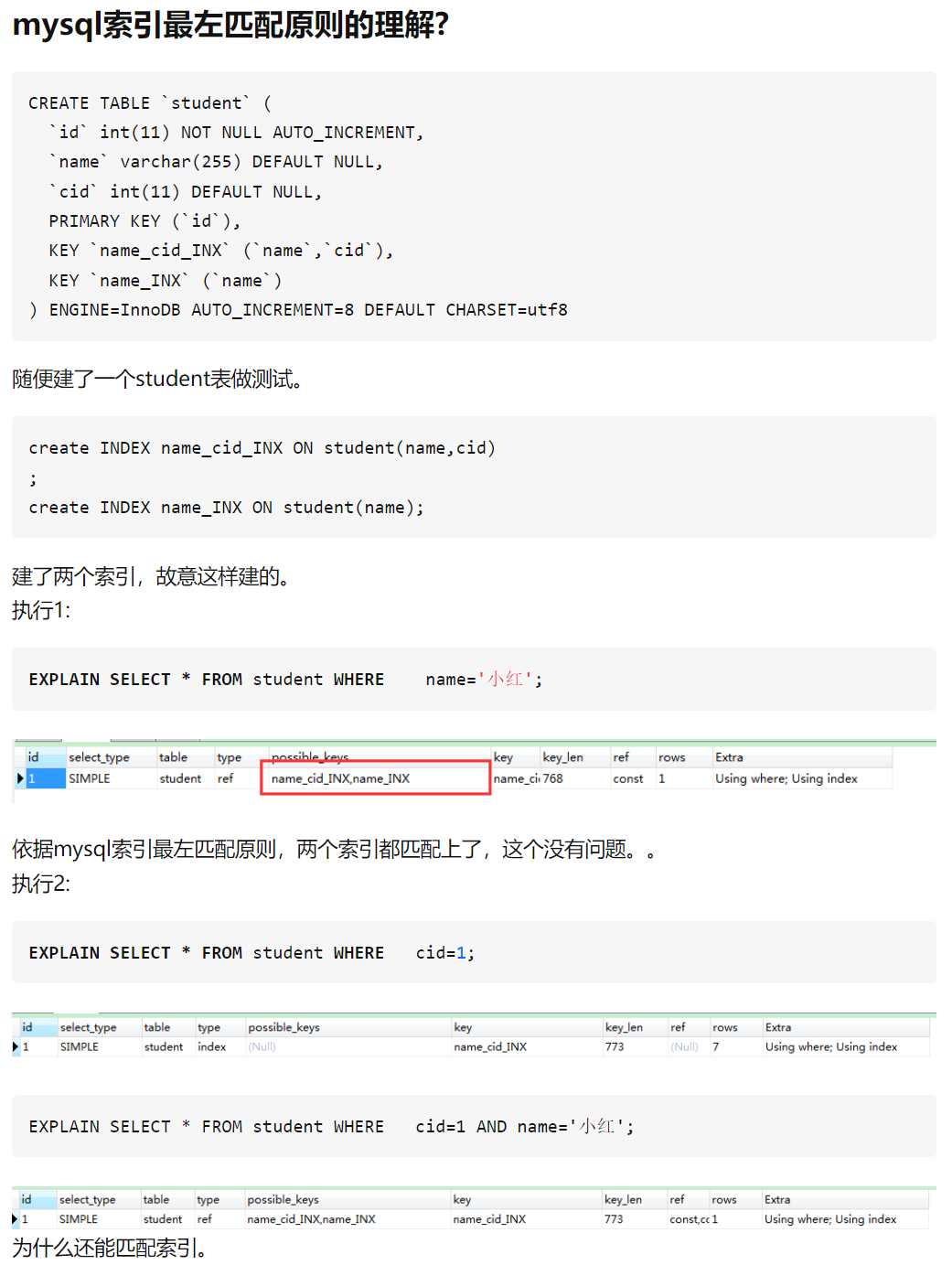
第一个问题
EXPLAIN SELECT * FROM student WHERE name=‘小红’;
这个能用索引很正常,没什么可讲的
看一眼执行计划

第二个问题
EXPLAIN SELECT * FROM student WHERE cid=1;
这个很有意思,为什么能用到索引呢?
先看看执行计划

我们注意到确实使用了索引,不过稍有不同,说的是 full index scan 和上边的 index scan 是不一样的,却别在于 full index scan(全索引扫描)也就是说要扫描整个索引(不能利用索引的有序性),index scan(索引扫描)这个可以利用索引的有序性,进行二分搜索
先说说你疑问的,这明明搜索条件是 cid 不符合最左前缀,为什么还是用了索引呢?
这里有个隐藏条件 KEY name_cid_INX(name, cid) 这个索引实际上是 KEY name_cid_INX (name, cid, id)
主键会自动附加在每一个索引的最后
那这么看还是不符合最左前缀呀?为什么是全索引扫描而不是全表扫描呢?
通常来讲,索引文件的大小是小于全表数据文件的(因为索引通常是其中的几个字段)
那你的这个 SQL 又刚好查的内容都在索引里有
这里为了方便,我把表结构,SQL和索引放一起看看
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
EXPLAIN SELECT * FROM student WHERE cid=1;
KEY `name_cid_INX` (`name`,`cid`,`id`)
select * 恰巧要找的数据就是 name, cid, id 这三个,又因为一般索引文件小于全数据文件,所以优化器就用全索引扫描了,扫描文件小自然更快
如果在表里再增加一个不在索引的字段,使用 select * 的话就会进行全表扫描了
alter table student add column_4 int null;
EXPLAIN SELECT * FROM student WHERE cid=1;

第三个问题
EXPLAIN SELECT * FROM student WHERE cid=1 AND name=‘小红’;
我猜你想问的是为什么两个索引都能用上
我们一个一个看
KEY name_cid_INX (name,cid)
这个 MySQL 有优化器,会自动调整条件顺序,来达到最佳性能(当然自动化就会有失误)
所以这个索引能命中很正常
那另一个呢?
KEY name_INX (name)
先根据 name 索引缩小结果集,在此之上过滤 cid = 1 的结果集,这肯定也是快于全表的,所以也没什么问题